【爬虫】FitGirl-Repack的Scrapy爬虫代码
今天花了一点时间,写了一个FitGirl Repacks游戏网站的自动爬虫脚本
用的是scrapy的爬虫框架
items.py 作用:确定需要爬取的内容
import scrapy
class Fg1Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
tle = scrapy.Field()
info = scrapy.Field()
pass
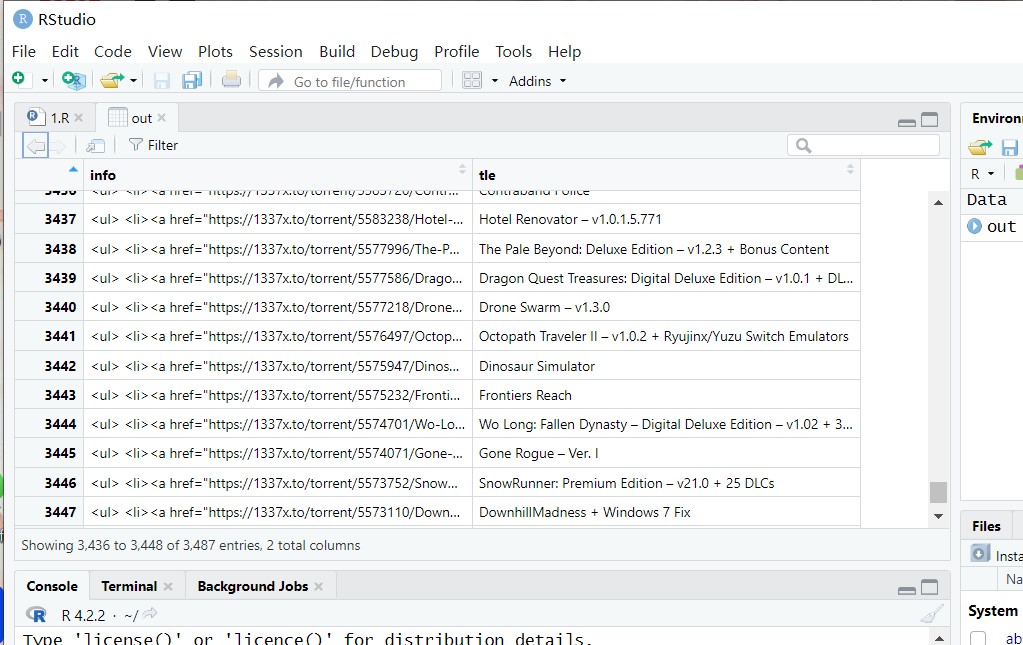
在这里,我选择爬取两样信息:title 和 info ,分别对应各个游戏的标题名称 和 下载地址
FG.py 作用:爬虫的逻辑结构
import scrapy
from FG1.items import Fg1Item
class FgSpider(scrapy.Spider):
name = "FG"
allowed_domains = ["fitgirl-repacks.site"]
start_urls = ["http://fitgirl-repacks.site/"]
def parse(self, response):
for i in range(1,350):
yield scrapy.Request("https://fitgirl-repacks.site/page/"+str(i)+'/',callback=self.parse_page)
pass
def parse_page(self, response):
for each in response.xpath("//article"):
item=Fg1Item()
item['tle']=each.xpath("header/h1/a/text()").extract()
item['info']=each.xpath("div/ul[1]").extract()
yield item
逻辑结构分为两层:
- 先获取索引界面,请求各个目录界面( parse 函数)
- 再用XPath解析 获取各个界面的title和info
运行 scrapy crawl FG -o out.csv
最后可以看到爬取了全部3千多条信息