机器学习12种分类模型的性能对比
接上回,我们已经知道了机器学习分类的本质,那么接下来就是要介绍机器学习中的分类模型的各种性能了。
简介
我们将采用12种分类模型,分别是:GaussianNB、MultinomialNB、KNNeighbors、SVC、DecisionTree、RandomForest、GradientBoosting、LGBM、XGB、CatBoost、AdaBoost、MLP,用这些模型对数据集进行训练,然后对测试集进行预测,最后将预测结果与真实结果进行对比,得到各个模型的性能。
数据集
我们采用以下代码生成随机分类数据:
x,y = make_classification(n_samples=100000,n_features=3,n_classes=4,n_informative=3,n_redundant=0,random_state=50,n_clusters_per_class=1)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.1)
这里能够生成100000个样本,每个样本有3个特征,4个类别,3个特征是有效特征,0个冗余特征,随机种子为50,每个类别有1个簇。然后我们将数据集分为训练集和测试集,测试集占10%.
由于每个样本都是一个3维向量,所以我们将数据取前2维数据将数据集可视化,如下图所示:
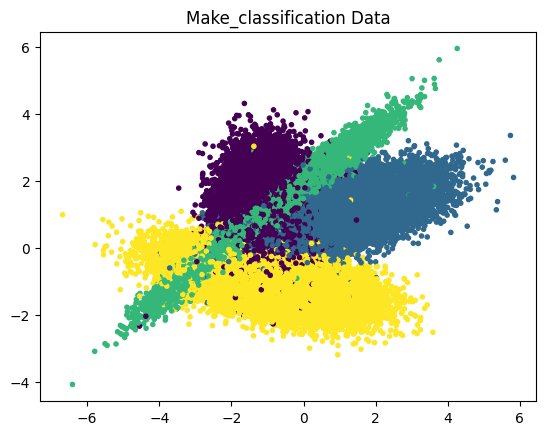
评估函数
我们采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值(F1-score)、R2值(R2-score),这5个指标来评估模型的性能。
准确率(Accuracy)
准确率是指分类正确的样本数占总样本数的比例,即:
其中,TP是真正例,TN是真负例,FP是假正例,FN是假负例。
精确率(Precision)
精确率是指分类正确的正例数占分类为正例的样本数的比例,即:
其中,TP是真正例,FP是假正例。
召回率(Recall)
召回率是指分类正确的正例数占真正例的比例,即:
其中,TP是真正例,FN是假负例。
F1值(F1-score)
F1值是精确率和召回率的调和平均数,即:
F1值越接近1,表明模型的性能越好。
R2值(R2-score)
R2值是指预测值与真实值的相关系数,即:
其中,是真实值,是预测值,是真实值的均值。
R2值越接近1,表明模型的性能越好。
各模型表现
1. GaussianNB
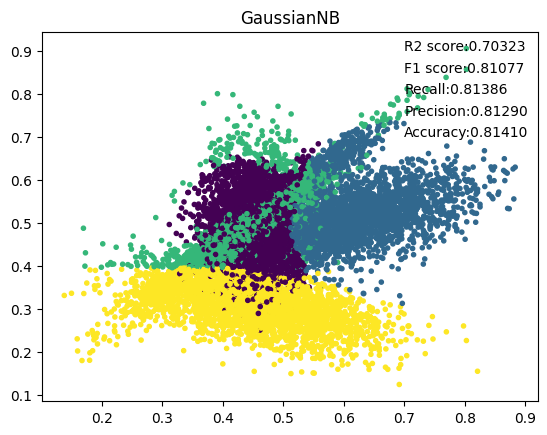
其中GaussianNB的参数priors为None,var_smoothing为1e-09,表明我们没有对先验概率进行设置,而且我们对方差进行了平滑处理。
2. MultinomialNB
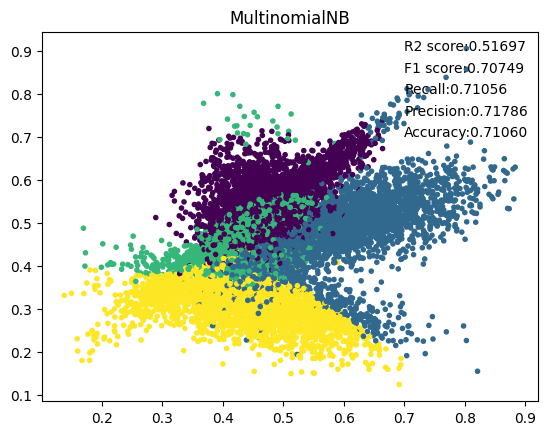
其中MultinomialNB的参数alpha为1.0,fit_prior为True,class_prior为None,表明我们对先验概率进行了设置,而且我们对先验概率进行了平滑处理。
3. KNNeighbors
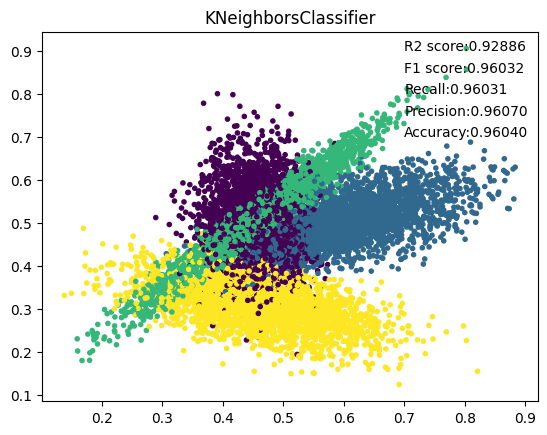
其中KNNeighbors的参数n_neighbors为30,表明我们对最近邻的个数为30。
4. SVC
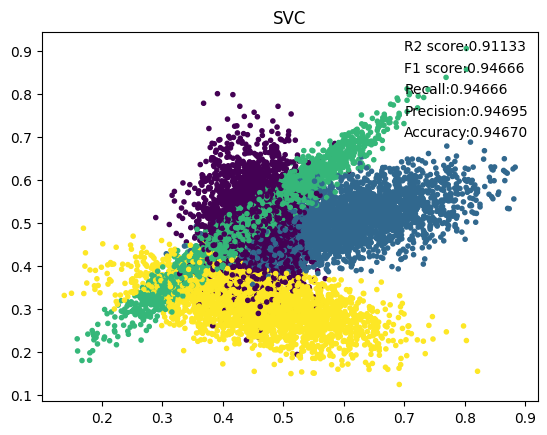
5. DecisionTree
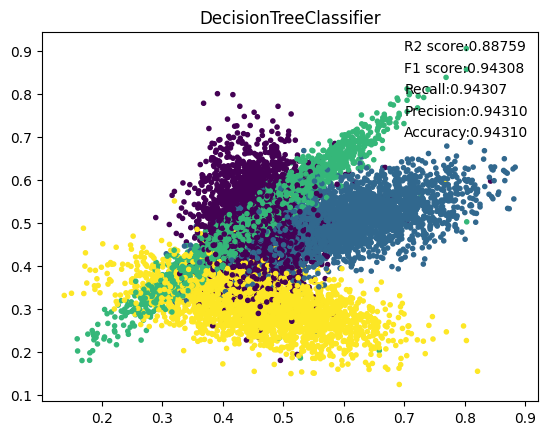
6. RandomForest
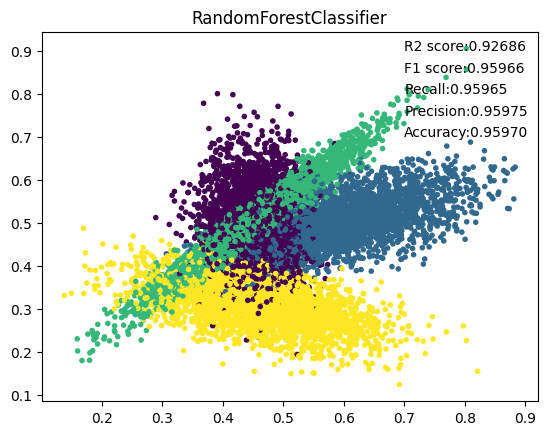
7. GradientBoosting
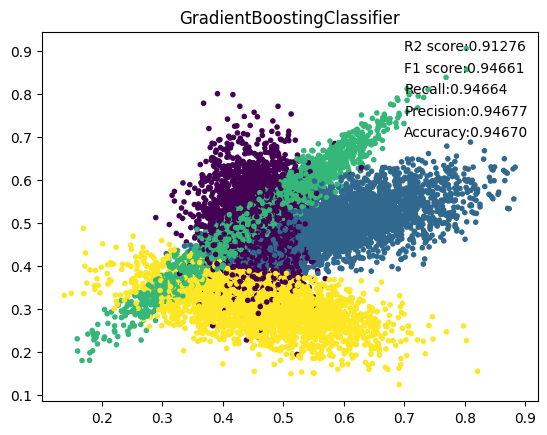
8. LGBM
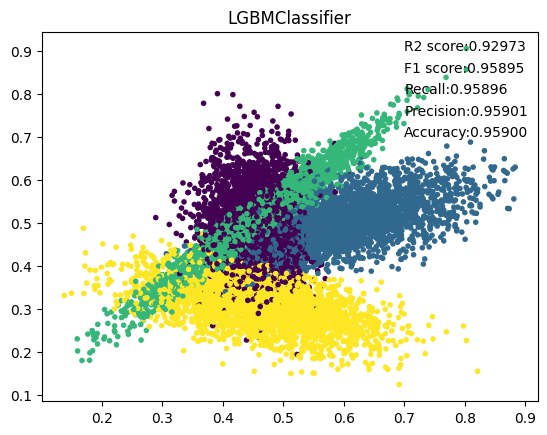
9. XGB
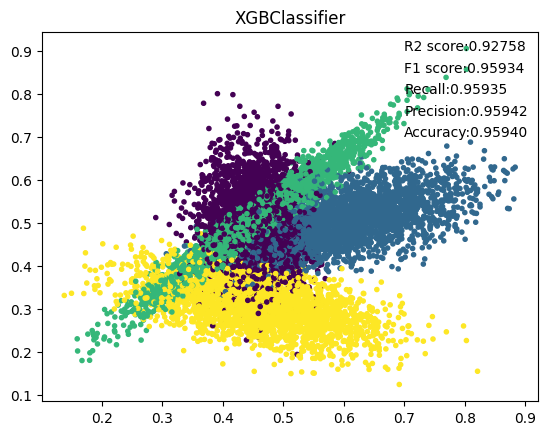
10. CatBoost
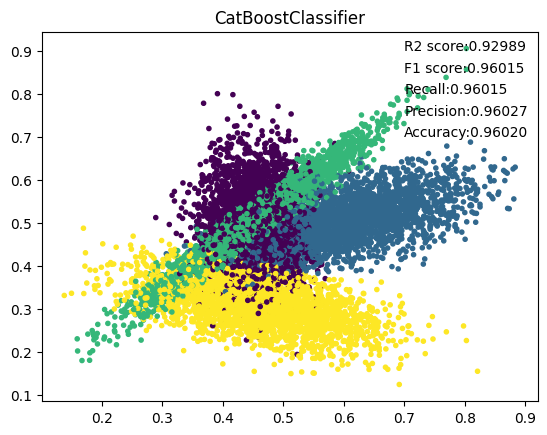
11. AdaBoost
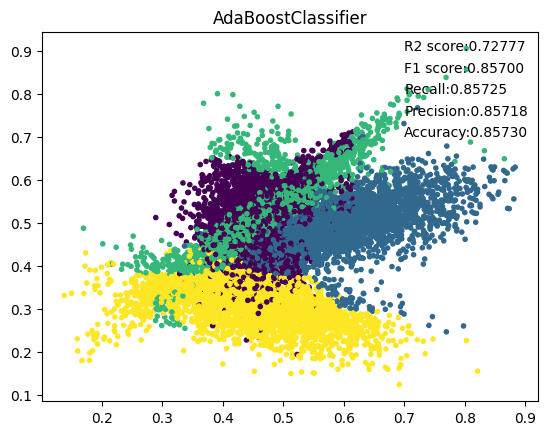
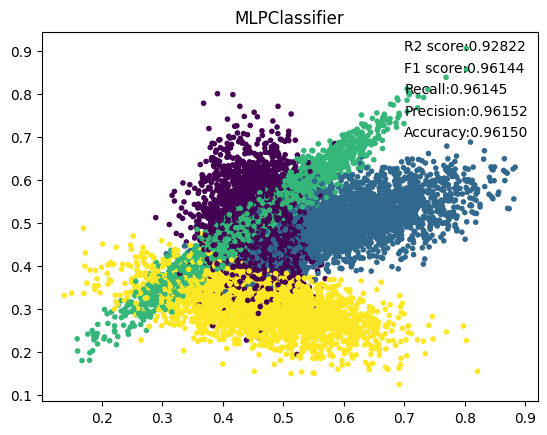
12. MLP
总结
MLP(神经网络模型)在准确率、精确率、召回率、F1值、R2值上的总体表现最好,这归于神经网络模型的强大的拟合能力。
其次是KNNeighbors(K近邻模型),K近邻模型的各项指标都很高,而且更值得一提的是:K近邻模型的训练速度非常快,也是所有模型中原理最简单的。
总体来说:判别模型的性能要优于生成模型,这是因为判别模型的假设空间更小,所以更容易拟合数据。
有一点猜想:生成模型是基于贝叶斯公式的,而贝叶斯公式是基于条件概率的,而条件概率是基于联合概率的。当样本数量很大时,样本噪声也会很大,这样计算联合概率就会很困难,计算概率的准确率也会很低,所以生成模型的性能就会很差。
# %%
#加载Intel的scikit-learn加速
from sklearnex import patch_sklearn
patch_sklearn(global_patch=True)
# %%
#用sklearn随机生成一个有3个分类的数据集,然后用KNN算法进行分类
from sklearn.datasets import make_classification
from sklearn.metrics import accuracy_score
from sklearn.metrics import r2_score # R2评分,R2值越接近1,表示模型越好,越接近0,表示模型越差
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
x,y = make_classification(n_samples=100000,n_features=3,n_classes=4,n_informative=3,n_redundant=0,random_state=50,n_clusters_per_class=1)
#取其中的两个维度进行绘图
import matplotlib.pyplot as plt
plt.title('Make_classification Data')
plt.scatter(x[:,0],x[:,1],marker='.',c=y)
plt.show()
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.1)
# %%
#将数据归一化,数据都是正数
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)
# %%
def accurate(title):
plt.title(title)
plt.scatter(x_test[:, 0], x_test[:, 1], marker='.', c=y_predict)
plt.text(0.7, 0.7, 'Accuracy:%.5f' % accuracy_score(y_test, y_predict))
plt.text(0.7, 0.75, 'Precision:%.5f' % precision_score(y_test, y_predict, average='macro'))
plt.text(0.7, 0.8, 'Recall:%.5f' % recall_score(y_test, y_predict, average='macro'))
plt.text(0.7, 0.85, 'F1 score:%.5f' % f1_score(y_test, y_predict, average='macro'))
plt.text(0.7, 0.9, 'R2 score:%.5f' % r2_score(y_test, y_predict))
plt.show()
# %%
# 用高斯贝叶斯算法进行分类
from sklearn.naive_bayes import GaussianNB, MultinomialNB
gnb = GaussianNB()
gnb.fit(x_train, y_train)
y_predict = gnb.predict(x_test)
accurate('GaussianNB')
# %%
#用多项式贝叶斯算法进行分类
mnb = MultinomialNB()
mnb.fit(x_train,y_train)
y_predict = mnb.predict(x_test)
accurate('MultinomialNB')
# %%
#用K近邻算法进行分类
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=30)
knn.fit(x_train,y_train)
y_predict = knn.predict(x_test)
accurate('KNeighborsClassifier')
# %%
#用SVM算法进行分类
from sklearn.svm import SVC
svm = SVC()
svm.fit(x_train,y_train)
y_predict = svm.predict(x_test)
accurate('SVC')
# %%
#用决策树算法进行分类
from sklearn.tree import DecisionTreeClassifier
dtc = DecisionTreeClassifier()
dtc.fit(x_train,y_train)
y_predict = dtc.predict(x_test)
accurate('DecisionTreeClassifier')
# %%
#用随机森林算法进行分类
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(x_train,y_train)
y_predict = rfc.predict(x_test)
accurate('RandomForestClassifier')
# %%
#用梯度提升算法进行分类
from sklearn.ensemble import GradientBoostingClassifier
gbc = GradientBoostingClassifier()
gbc.fit(x_train,y_train)
y_predict = gbc.predict(x_test)
accurate('GradientBoostingClassifier')
# %%
#用LightGBM算法进行分类
from lightgbm import LGBMClassifier
lgbmc = LGBMClassifier()
lgbmc.fit(x_train,y_train)
y_predict = lgbmc.predict(x_test)
accurate('LGBMClassifier')
# %%
#用XGBoost算法进行分类
from xgboost import XGBClassifier
xgbc = XGBClassifier()
xgbc.fit(x_train,y_train)
y_predict = xgbc.predict(x_test)
accurate('XGBClassifier')
# %%
#用CatBoost算法进行分类
from catboost import CatBoostClassifier
cbc = CatBoostClassifier()
cbc.fit(x_train,y_train)
y_predict = cbc.predict(x_test)
# %%
accurate('CatBoostClassifier')
# %%
#用AdaBoost算法进行分类
from sklearn.ensemble import AdaBoostClassifier
abc = AdaBoostClassifier()
abc.fit(x_train,y_train)
y_predict = abc.predict(x_test)
accurate('AdaBoostClassifier')
# %%
#用神经网络算法进行分类
from sklearn.neural_network import MLPClassifier
mlp = MLPClassifier()
mlp.fit(x_train,y_train)
y_predict = mlp.predict(x_test)
accurate('MLPClassifier')